
In this rather long read (~4.600 words, ~20 min) I’d like to share some of the thoughts and ideas that helped us through a high risk project.
Application Migration
What do you do when you are given the assignment to migrate your application from one data center to another? And what do you do when it turns out you need to get a different database as well? How do you execute an assignment of this scope? How do you deal with the high levels of uncertainty? And how do you make sure your people stay focused all this time?
Those were some of the challenges our team was confronted with over the nine months it took to get the job done. In this rather long story I’ll try to explain how we acted and show some of the things we did to make our jobs a little easier or less risky. I myself am a coder, but I won’t limit myself to just that. To be honest, the most interesting stuff didn’t have much to do with writing code at all.

Our end product turned out to be quite the success. I know that this sounds rather weird, it being a big IT project and all, but it is the honest truth. We pretty much hit the deadline we set for ourselves, we saved the people in charge a ton of money while staying below (!) the estimated budget. We also introduced a lot of test automation tooling, CI and the customer was delighted with a 100%+ performance improvement.
We as a team feel that the way in which we acted played a crucial role in it all. We chose a very pragmatic, agile approach. I hope the remainder of this post will adequately show you how we acted, how we made decisions and how we solved some of the issues we faced along the way. Being agile is a mindset, but in order to be agile you need support from your surroundings: the teams, management, other stake holders, but also from your tooling.
This post will not be about the individuals or the specifics of the assignment, product or client. They are irrelevant to the story we want to share. All of the examples used did actually happen the way they happened, when they happened, but serve no purpose other than to help the story to be told. For reference though, our core project team consisted of members with the following main skills:
- Java Programmers (3 on average)
- Testers (2)
- Technical (1)
- Coordinator (1)
- DBA (1)
- Ops (1)
- Facilitator (1)
- Product Owner (1)
We operated within an environment that had multiple agile teams working on different parts of a bigger application landscape. For the duration of this project, our team was dedicated to work on this one specific application.
Day 0 – challenge accepted
The whole thing started when a request came in to move one of our applications from one data center to another. The application was a legacy system that had been maintained and built upon for the last decade or so. It did not have unit tests, it did not have automated test scripts, performance testing of any kind or a lot of regression test cases. There was no performance benchmark other than that the current production hardware could run the system reasonably well.
 The system was a Java application that made use of several different libraries and frameworks. The biggest one by far was a now outdated version of Oracle ATG. ATG is a big e-commerce platform, but our application had nothing to do with e-commerce at all. It was only used for its ORM, DI and front-end libraries. Rather standard things in a lot of today’s Java frameworks. It also provided mechanisms for queueing, caching and job scheduling. Back in the old days, it was introduced because the licenses were there, the expertise was there and it did solve some problems. Nowadays it is more of an annoyance than a useful tool. But since it is woven into every layer of the application, we were kind of stuck with it.
The system was a Java application that made use of several different libraries and frameworks. The biggest one by far was a now outdated version of Oracle ATG. ATG is a big e-commerce platform, but our application had nothing to do with e-commerce at all. It was only used for its ORM, DI and front-end libraries. Rather standard things in a lot of today’s Java frameworks. It also provided mechanisms for queueing, caching and job scheduling. Back in the old days, it was introduced because the licenses were there, the expertise was there and it did solve some problems. Nowadays it is more of an annoyance than a useful tool. But since it is woven into every layer of the application, we were kind of stuck with it.
Once (manually) tested, the code base could be deployed to any given system in about an hour. There was a custom tool with which to do these deployments, but we had already started making progress on introducing Jenkins combined with Sonar for nightly builds and some code analysis. The results at this point were rather scary. Chuck Norris would have roundhouse kicked us into the depths of programmer hell if he’d have seen it.
Day 1 – determining scope – what just happened?
The team got together to think about the implications of moving to a different data center. To not move wasn’t an option. Contracts had been terminated and the servers had been on the verge of death for a while now. Still a move was seen as risky, because of our lacking ability to test and put benchmarks on the software. But this wasn’t going to be the only problem.

As it turns out, ATG uses licenses. Rather expensive ones at that. Our application could always make use of the department’s licenses, so the costs were never really an issue. However, new licenses had to be bought to be able to run on new physical servers and the department as a whole was looking at ditching ATG. Not because it was a bad product, but because we didn’t do e-commerce. In other words, we could not migrate to new servers as long as our code used ATG. Then came problem number two: the Oracle database. Similar issues with licensing applied here, so no migration without also replacing the database. We would have chosen a free DB, but we could also lift on the department’s SQL Server licenses. The choice for the latter was made due to available expertise, which meant less risk. Something we could use at this point.
So after one day we went from a data center move to a data center move ++. Move to a different data center, get rid of ATG and switch from an Oracle to a SQL Server DB. Whew. Normally no sane human being would ever start with something like this, but we did anyway.
Day 10 – planning and estimation
Two weeks have past. We made an inventory of our existing code base, database, frameworks, libraries etc. We asked all testers for any test scripts and tools they might have. We got ops to tell us which tooling they used. We could finally compile a list of all most of the things that needed to be done. The team quickly concluded that without proper (regression/performance) testing the whole endeavour was destined to fail.
Next up: estimation sessions. We started by accepting the team’s inability to make detailed predictions on how long each task was going to take to complete. There was too much uncertainty at this point and we felt that if we were to invest several days into a more detailed work breakdown, it wouldn’t result in a more accurate planning. So instead, we chose not to make any detailed tasks. We made epics. Each application module became an epic, test automation became an epic, getting a new database became an epic, getting a new test environment became one and so on.
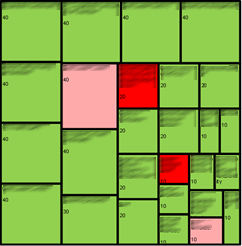
Each epic would be given a development and a test size: S, M, L and XL. They would roughly translate to 1, 2, 4 and 8 weeks of work. A database epic and coding epic could be done simultaneously. Combining all this, we could see that it would result in roughly 8 months of work for our team. We assumed that every once in a while an S would become an M, but similarly an L could become an M. The team’s gut feeling also supported the 8 month time frame.
Tracking progress was extremely black and white. An epic is done or it is not. We used traffic light colour coding for this. Red meant it hadn’t been started. Yellow (pink in the image for some reason) meant in progress and green meant it was done. This means some weeks we made no progress at all, while other weeks we completed 8 weeks worth of work. As long as it evened out in the long run, this was fine.
Day 15 – the agile way of working
The team had a set-in-stone end goal: move to new data center, switch database, migrate code, no regression in functionality and performance. We also had a planned running time of about 8 months. The next question was how do we make sure we hit our target? The short answer was ‘Agile’. Due to the many uncertainties it was deemed impossible to make a plan we could stick to. We needed to be able to change our planning on the fly. So we wanted a flexible plan and a very simple one. Agile was the perfect fit.

But how were we going to be agile exactly? Do we want scrum? Do we need sprints? Planning poker? How do we keep focus on reaching our end goal? We ended up choosing our own set of rules. They most resembled a Kanban style of working. We decided that trying to work in sprints would only hamper our velocity. A free format style of working seemed to fit much better. Pick the highest business value, highest risk epic and finish it front to back.
We used Trello as our electronic task board of choice. It did exactly what we needed and nothing more. This is important, because tooling should always support you in your way of working. A tool should never force you to work in a certain way. Many hours later, we had dozens of small tasks in our left-most column, the backlog. These came from breaking down the most important epics into smaller tasks. The idea was to pick up all tasks for one epic and get them all the way to the right of the board. From Backlog > In Progress > Ready For Test > Tested > UA Tested > Done.
Now, all of that sounds nice in theory, but in reality things just do not work that way. You quickly become blocked in one way or another and you have start working on another epic. Pretty soon, half of them are marked as In Progress (yellow). To avoid losing focus and control, it was quickly decided to really try and stick to the original plan. And if it just wasn’t possible, to try and work on as few other epics as you could. Experience taught us that working on too many things at once kills productivity, quality and morale.
Our release train stopped in our UA environment, since we had to go to production all at once. But being able to test one feature area as if it were to go to production afterwards is still a good thing. It gives you feedback from actual users. They always manage to do things in ways you did not anticipate, so getting their feedback early on is very helpful. It also reduces the risk of having one gigantic make-or-break UA test run near the go-live moment. Of course we still had that final UA test run, but since most things were tested before, we felt very confident in the result at that point.
Day 20 – one week under way – well, not really
Officially we just finished our first week of programming and testing. We had already experimented with some spike solutions in the weeks prior to this one to get a better grasp on how large the task at hand was going to be. The biggest spike we made gave us a lot of useful information about the project’s size, but it also gave us a good idea of where the complex code lived. The main spike included providing a basic module setup, a working maven installation and we had some basic test (web app test, db connection test, etc.) modules we could deploy to our local dev servers. We used our old Oracle dev database for now. We also hijacked one of our to-be-removed test environments to deploy to for the time being.

CheckStyle, PMD etc.
In other words: Continuous Integration (CI) from the get go. This is becoming a recurring theme, but possibly the most important one. Get as much feedback as you can, as frequently as you can. The earlier on the better. From day one we were testing and tweaking our release process, organising nightly deployments, daily quality checks and so on. We switched from SVN to GIT. We needed a new VCS server and decided on GIT since we felt it would help with making small POC branches, merging and sharing code. Finally, we switched IDE from Eclipse (free) to Intellij (licensed) because it improves our coding speed, has better GIT (file merge) integration, tooling support, refactoring tools and a lot of other small goodies.
Looking at the code modules, we had to pick new technologies to replace their ATG counterparts. We went with market standard open source, mostly so we wouldn’t face any licensing and recruiting issues. We decided to keep many of the smaller libraries so that we wouldn’t have to rewrite too much code. We did look at upgrading them to their latest versions whenever possible. Aside from caching, we were done picking our libraries. We were hoping we could get away without caching. so we postponed deciding on this until later.
Of course things changed later on. Certain libraries just didn’t work, were no longer supported or were a nightmare to work with. The idea is to get a stable environment early on and tweak it as you go and gain more experience with the new code, tools and environments. Try to make your final decisions only when you really have to. Keeping it open gives you the flexibility to change if the need arises.
Day n mod 5 == 0
We would not do a daily stand-up as we only had one team doing all the work. We sat together in one room, so if there was a problem it could be dealt with on the spot, not the next morning. Instead we held a weekly planning session. Not to plan any new work, but to see if we were still on track. During these sessions, we often had to change the size of one of our epics. We changed priorities almost every week. The first few meetings ended with the same question each time: can we still make it?

During the weekly meeting, we looked at each epic to see its progress. In theory, finishing one thing before starting the next sounds great. In practice it is not always so easy. Often you get blocked by external factors. The database isn’t ready, our server is still being worked on, Team X is supposed to change their code before we can proceed, we need a management decision. But more on that later.
Day 60 – three months underway
Our first epics are turning green. Many are still yellow, some are still red. We finished some of the more risky parts of the application backbone. Jenkins, Sonar and GIT are alive on the new servers. The database is almost ready. Sonar is getting happier by the week. Our testers are not. A lot of test scripts are being written, but all testing is still done manually. The project scope does not allow writing loads of new unit tests either (no time). Houston, we have a problem!
We already run our team using the boy-scout rule wherever we can. At the very least, just copy-paste stuff. We decided to only write unit tests for the craziest parts of the system. Things that would be difficult to automate later, high risk sections of the code base and so on. Finding the right balance here can be tricky, since the good programmer in you just wants to write tests everywhere.
Day 70 – chop chop – finding a solution
We decided that we cannot go on without proper automated testing tools. One of our team members wrote an extension to our manual test tool. We can now write test cases and automate them. That is, even the testers can write automated tests. This is especially important, because as a programmer I do not want to perform system tests or write them for my own code. A tester is much better at finding edge cases, determining proper test values, different execution paths and so on. A programmer’s main job is to build the system, a tester’s job is to break it.

Day 80 – performance testing and priorities
Early on we decided that in order to deliver a reliable product, we must also have executed performance tests. Our new system must be able to deal with the current production load and some more. However, we still do not have any performance test tooling. We delegated this bit of work to another team, but they were given other priorities.
This happened to us a lot, and it happens a lot everywhere. Other people and teams have their own goals and priorities, so the motivation we had to work on our product wasn’t always shared. This is to be expected of course, but it is still annoying. We learned that if something important needs to be done, if possible, do it yourself. Or make sure it gets enough priority in another team. But do not sit back and wait for ‘them’ to finish it or make decisions.
So with regression test tooling in place, the step to make a performance test tool out of it was much smaller. A lot of the work was taken back to the team to make progress where the lack of priority was hampering the other teams from doing it for us. This goes for many things. Remember that it is you who wants something done quickly. The other party might not care as much, so it is your task to get the things you need.
Day 100 – performance, oh crap…
We are now at a point where the core of the application is done. Sending a request to the application results in realistic processing on the back-end. The performance is… uh… where is my response?

We are experiencing the same issues that our old code faced. Certain requests need to end up in the application cache before subsequent calls perform. We did not have any caching yet, because the implementation we chose didn’t work (yet) and because we first wanted to see if we really needed it. So do we need it now? Maybe. First it is time for some code analysis and cleanup. Instead of getting ourselves a working caching implementation, we decided to tackle the root cause of the problem first.
It meant a little setback in time, but a programmer’s gotta do what a programmer’s gotta do. Reducing the query count from thousands to two dozen for certain requests sure helped. Rewriting some of them did too. A revamp of a bit of code that up until now was labeled too-scary-to-touch gave the final push. We now outperformed the old code, without having a cache. Holy flip-flop, batman!
Getting the cache implementation up and running just became a bonus feature. Eventually we learned that it broke because of a bug in Hibernate, but it no longer mattered as much. Tackling a problem at its core is much more valuable than putting another patch over it and hoping it will hold.
Day 120 – Happy New Year!
We are getting there. All those green squares are starting to look very nice. Our Trello board is slowly clearing up. There is this weird thing with being unable to make remote calls, but after a server restart it could not be reproduced. There are also some issues with performance testing, but overall things look good.

Our team has evolved over the past few months. Each team member has been doing a lot of pairing with people from other disciplines. During the holiday period the ops guy and all the programmers left to be with their families. Our poor tester had to run the show for at least two weeks. He ended up grepping server logs, restarting environments and hacking the database. Our programmers know how to configure the server, maintain the database and work with test tooling. This is getting seriously agile: a proper cross-functional team.
Day 140 – T-minus 1 month
The code is finished aside from the incidental bug report. We moved from system test to user acceptance testing. We are mostly getting positive feedback. The go-live slot has been granted and we are getting ready for an all-nighter. We planned for a six hour outage. It takes our DBA roughly four hours to copy our production database, migrate it from Oracle to a SQL Server format, load it and perform clean-up scripts. The remaining two hours are reserved for putting the code live, turning on the servers, smoke tests and making traffic point to the new location.
We switched from our weekly meeting to doing a form of daily stand-ups. This close to our deadline, we simply couldn’t afford potentially waiting a week with an issue. The stand-ups were much like those in scrum, but they were not time boxed. It was more important to cover all topics than to stick to a ritual.
Day 150 – T-minus 2 weeks
Performance tests indicate we should easily be able to handle the traffic load we experience or the current production environment. UAT is almost done and we have no issues left. Our testers are spending their time automating more and more test cases.
Developers at this point are not doing that much. They are helping out wherever they can, but no changes are made to the code, unless it is to fix a bug or do things like writing JavaDoc or making some styling fixes.
We started looking at the tasks that were not picked up or completed. It turned out there were quite a few. Most of them turned out to be tasks that could also be done after our production go-live. We added a new column on Trello to create an aftercare backlog. This way the team could focus on the few remaining cards they did have to finish during the final two weeks.
Day 158 – T-minus 2 days
Being agile is a combination of behaviour and tools. How can you quickly adapt to change if you are drowning in process? How can your team stay productive if all they know is their own domain and someone gets ill or goes on a holiday? How are you going to generate short feedback loops without a CI server? Or without automated tests? You can’t.
It turns out our newest automated test set is able to kill an entire environment. Uh oh, our Christmas-time bug has returned with a vengeance. Great timing too. This time we could reproduce it and fix it just in time.

If we didn’t have the test automation we had, this would’ve caused an immediate outage and lots of customer complaints just moments after the go-live. It goes to show the importance of tooling like this. We could fix the issue, re-run all regression tests and performance tests within a day. We spent the final day doing a quick UAT ourselves. We felt comfortable we had fixed the issue for good without introducing any new problems.
Yeah of course you could say we also had a lot of luck. The tester could have easily picked another feature area to make automated tests for. But because this was the most critical area that was left, it was chosen. If we would have had less tests or wouldn’t have had anything at all, he would indeed have worked on another area. So was it pure luck nothing bad happened or did we avert this issue ourselves?
Day 160 – i want for you to experience big bang
It is midnight. Armed with a gigantic load of coffee, sugar and other junk food the entire team sat in the office, ready to flick the switch. We only needed two or three people there, but instead there were at least a dozen of us present. We all felt that we had to be there. It took us 9 months to get this far, and we sure as heck were not going to miss the final moments.
The next morning we were live. Everything was stable, no outages, bugs or customer complaints came in. We just sat there, kept awake by inhuman dosages of caffeine and sugar, looking at the monitoring tools. We did many test runs before this final one, but we were still relieved we didn’t have to cancel or roll back.
Wrapping up
Now, some months later, we are still running like a charm. Some issues came to light, as happens with every big client facing application, but nothing major. None of this would have been possible if we didn’t have the people we did. Their truly agile mindset made things run as smooth as it did. Nobody was afraid to step outside their comfort zone and become a cross functional professional. Nobody was afraid to show initiative or share ideas. Everyone had an innate drive to get the right things done. Without that, there would have been no test automation, no performance tests and the code would still perform poorly.

The summary or: How we learned to stop worrying and love agile
- Picking your own tools, coming up with solutions yourself and fixing the problems you introduce make you feel responsible for the code you write or the product you test. It makes you care. If you care, you do not settle with second best solutions. Not if you can help it.
- Freedom is great. We all like to be able to make our own choices instead of being told what to do by others. Some boundaries need to be set though, otherwise the result is anarchy. It is up to management to facilitate teams by providing clear goals, context and boundaries. And a stable environment to work in. Within that context, teams should be left free to do what they think is best.

- Having goals to work towards is motivating. The big goal on the horizon is great, but having smaller goals you can reach in the short term keeps you motivated. Always actively trying to only do those things that get you to your end goal keeps you focused. It keeps you from losing interest or getting lost in a giant pile of tasks and bugs.
- Having an agile mindset and creating processes around this helps you deal with high uncertainty. Unclear specs, scary pieces of legacy code, unknown systems or dependencies on external parties might require you to adjust your plan a lot. If you know this will likely be the case with your product, create an environment for yourself in which you can make these changes easily.
- Shorten your feedback loop! The sooner your automated test tooling tells you that you have a problem, the sooner you can roll back or fix it. It saves enormous amounts of time in the long run – heck, even the short run – and makes your software that much more reliable. Keep communicating within the team, but also with the outside world. Quick feedback is key here too. Do not overdo it though. Nothing is worse than a two hour meeting that serves no real purpose.


{kind=link}